
Blog article
Comparing Pinnacle (Pascal) and EZRA (Cai)
Comparing Pinnacle (Pascal) and EZRA (Cai) for AI coaching in 2026. Learn how these two platforms differ, and which is the right fit for your organization.

Not all AI coaches are built the same. Some help individuals reflect. Others are designed to change how your organization actually operates.
This guide breaks down where Valence (Nadia) fits, where it falls short, and why Pinnacle and its AI Coach, Pascal, are a fundamentally different category of AI coaching.
Before diving into the comparison, here's what to look for when choosing an AI coach for your organization:
Does it show up in the flow of work? The best coaching doesn't live in a separate app. It's embedded where leadership actually happens, in meetings, in Slack, in the moments between decisions.
Does it know your people, or just what they type? Most AI coaches only know what employees tell them. That means managers start from scratch every conversation, and the coach only ever gets one side of the story. Look for a platform that builds context over time.
Does it drive behavior change, or just reflection? Insight is a starting point. The real question is: can the platform show you that leadership habits are actually shifting?
Does it align with your culture, or just generic best practices? Your leadership principles aren't the same as everyone else's. Your coaching platform should reinforce the specific behaviors your organization cares about.
Is it proactive, or does it wait to be asked? A coach that only helps when someone opens the app will always be limited by who remembers to show up. The most impactful platforms reach out with feedback and guidance without the user having to initiate.
.png)
Claude, paired with an agent framework and custom skills, is designed for engineering-led organizations that want to build their own AI infrastructure rather than buy a finished product. The appeal is real: you get full control over the architecture, the data model, and how the system evolves — and you start from a foundation model that is genuinely capable.
This path tends to attract two types of organizations. The first has an internal AI team that is already building with Claude or similar models and sees adding a coaching use case as an extension of existing work. The second has a strong philosophical preference for owning their stack — either for data sovereignty reasons, deep customization requirements, or because they want to avoid vendor dependency in a category they consider strategically important.
The agent path works well at the prototype stage. The challenges emerge when organizations try to scale from a functional demo to a production system that HR is willing to stake a development program on.
The limits are not primarily about Claude's capability, they're about what the system around Claude needs to do. Persistent behavioral memory, live meeting presence, proactive outreach calibrated to individual goals, multi-stage retrieval across overlapping leadership frameworks, and enterprise-grade guardrails are each solvable engineering problems. The issue is that they're separate engineering problems, each with its own failure modes, and solving all of them to production quality takes significantly longer than most teams initially estimate.
It's also worth being direct about the layer agents don't provide: leadership science depth. An agent framework tells Claude where to look, it doesn't give Claude what to find. The coaching rubrics, behavioral evaluation loops, and research-grounded practices that make coaching specific rather than plausible have to come from somewhere. If your organization doesn't have that content layer, a well-built agent system will retrieve your framework documents more efficiently, but the coaching it generates will still reflect general best practices, not a validated approach to behavior change.
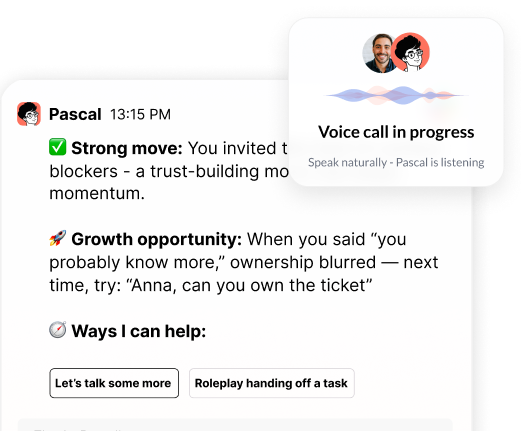
Pinnacle treats AI coaching as a performance system, not a reflective tool. Where other AI ask, "What are you thinking?", Pascal asks, "Here's what happened in your latest meeting, let's work on it."
Pascal is a coach and leadership companion. He joins real meetings, 1:1s, team conversations, and builds a complete picture of each leader's challenges and strengths without requiring constant manual input. This means Pascal knows how a manager's last 1:1 actually went, not just how they remember it. He sees team dynamics, communication patterns, and decision-making in real time.
Pascal lives in Slack, Zoom and Teams, so coaching surfaces where managers already work, not in a separate tool they have to remember to open.
Most AI coaches only know what employees tell them. Pascal is built on a proprietary knowledge graph that maintains persistent memory across all conversations and channels.
Pascal operates across three layers of context:
Over time, Pascal learns about each manager. He remembers the delegation conversation from last week, the pattern of rushed project handoffs, individual communication styles across contexts, and the goals they're working through. Managers never start from scratch.
Pascal is also proactive by design - he doesn't wait to be asked. After meetings (or on a daily or weekly basis), he offers proactive feedback tied to each leader's unique goals. After an important conversation, Pascal reaches out with specific observations on what went well and what could improve next time.
Pinnacle tends to be the stronger choice when:
There’s a meaningful difference between a raw prompted Claude instance, a well-built Claude agent system with skills and memory, and Pascal. The table below shows where each tier actually stands on the capabilities that determine whether coaching changes behavior.
Agents genuinely move the dial on the objections that made raw LLMs a non-starter for enterprise coaching. But a lot of limitations still remain after the agent framework is in place.
A Claude agent build is a legitimate path if the conditions are right. It’s worth pursuing when:
If those conditions are met, an agent-based build can reach meaningful coaching capability, though it will take longer and cost more than most teams initially estimate, and will require ongoing engineering investment that a purpose-built platform absorbs for you.
Agents route to content. They don’t generate coaching expertise. The 50+ leadership frameworks, 400+ research-based practices, coaching rubrics, behavioral evaluation loops, and people science that underpin Pascal’s guidance took years to build and validate. An agent framework tells Claude where to look; it doesn’t give Claude what to find. If you don’t have that content layer, you’re still getting generic best practices — just retrieved more efficiently.
Use Claude with agents if you have the engineering capacity and timeline to build, existing leadership content to ground the system in, and full ownership of the architecture is a strategic priority worth the ongoing investment.
Use Pascal if you need coaching in production now, want it to show up after every meeting without any manager action, and need behavior change at scale, not a system you have to build, maintain, and prove.

.png)
.webp)
“Thank you for setting the great foundation for my promotion; now I have a plan!"

Curious to see how AI Coaching can 10X the impact and scale of your development initiatives. Book a demo today for:


